Computer vision models (CVMs) can accurately label incidental breast findings on chest CT, according to a poster presentation given at the Society for Imaging Informatics in Medicine (SIIM) annual meeting in Pittsburgh.
Researchers led by Benjamin Rush, PhD, from the University of Wisconsin in Madison showed in their study that CVMs outperform large language models (LLMs) in labeling incidental breast abnormalities on chest CT.
“Continued comparison of AI versus AI could work at scale,” Rush and colleagues wrote.
Incidental breast abnormalities are found in between 1% and 7% of chest CT scans. Of these cases, about 30% are malignant. These findings may be overlooked since they are not the primary reason for a chest CT exam.
Rush and colleagues highlighted CVMs and LLMs as potential ways to help radiologists identify breast abnormalities for review. However, these need validation in real-world data sets before they can be implemented into clinics.
The researchers tested the performance of both types of models using data collected between 2015 and 2017 from 17,752 chest CTs in women ages 40 to 72 years. For the study, they used Covera Health’s CVM and the Qwen2 7B LLM.
The CVM labeled 82.6% of exams as negative and 7% as positive, while the LLM labeled 96.5% of exams as negative and 3.3% as positive. Both models showed agreement on 80.7% of exams both labeled as negative and 1.2% of exams labeled as positive.
Human adjudicators settled disagreements between the models.
While both models showed comparable performance in terms of accuracy, specificity, and negative predictive value (NPV), the CVM showed higher sensitivity and F1 score. The LLM meanwhile showed slightly higher positive predictive value (PPV).
Performance of CVM, LLM in labeling incidental breast abnormalities on chest CT | ||
Measure | LLM | CVM |
Accuracy | 95.7% | 97.5% |
Sensitivity | 39.8% | 81.9% |
Specificity | 99.4% | 98.6% |
PPV | 82.0% | 79.7% |
NPV | 96.1% | 98.8% |
F1 | 0.54 | 0.81 |
The researchers highlighted that AI versus AI comparisons with random human adjudicators “might be best” for real-world data validation of new AI and machine learning software.
They also wrote that future work will use larger or medical-specific models for better labeling of text-based incidental findings.
Read AuntMinnie’s conference page for full coverage of SIIM 2026.

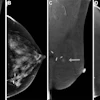








![A normal mammogram confirmed by three-year radiologic follow-up illustrates reader-marked regions of interest (ROIs) during (A) unaided (round 1) and (B) artificial intelligence (AI)–assisted (round 2) reading. Each colored dot represents an ROI for recall by a human reader. Readers could mark more than one ROI per case, represented by multiple dots of the same color. During AI-assisted reading, the AI system displayed three visible prompts: two with suspicion of malignancy scores of 35% (left mediolateral oblique [L MLO] and craniocaudal [L CC]) and one with a suspicion of malignancy score of 10% (right craniocaudal [R CC]), shown as polygonal overlays. Without AI, six of 10 readers (60%) marked a false-positive ROI. With AI assistance, this fell to two of 10 (20%). R MLO = right mediolateral oblique.](https://img.auntminnie.com/mindful/smg/workspaces/default/uploads/2026/07/2026-07-14-radiology-mammogram-ai-auto-bias.H0bYO8QlWs.jpg?auto=format%2Ccompress&dpr=2&fit=crop&h=167&q=70&w=250)




