Medical imaging artificial intelligence (AI) algorithms could be vulnerable to special attacks designed to induce errors, and bad actors have both the opportunity and incentive to engage in these hard-to-detect attacks, according to research published recently on arXiv.org.
These attacks, called adversarial attacks, employ inputs engineered to produce classification errors in deep-learning models. In testing, researchers led by Samuel Finlayson of Harvard Medical School in Boston found these methods could render highly accurate AI systems almost totally ineffective.
"We urge caution in deploying deep-learning systems in clinical settings and encourage the machine-learning community to further investigate the domain-specific characteristics of medical-learning systems," the authors wrote.
To demonstrate the vulnerability of AI in imaging, the researchers simulated adversarial attacks on AI algorithms designed to classify images for three different applications: chest x-ray, fundoscopy, and dermoscopy.
The group deployed several types of attacks, including projected gradient descent (PGD) attacks, which involve crafting distinct noise and applying it to each image, and a type of attack called adversarial patch of images. In addition, the team created an additional study control by using natural image patches in an attack.
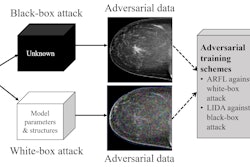
The researchers tested "white-box" and "black-box" methods for both PGD and patch-based attacks. The white-box attacks build attacks directly on the victim model itself, while black-box attacks involve crafting attacks against an independently trained model with the same architecture and then transferring the resultant adversarial examples to the victim model, according to the authors.
All adversarial attacks were found to be extremely successful, reducing the accuracy of the algorithm.
| Performance of chest x-ray AI model after adversarial attack | ||||||
| With clean training dataset | After PGD, white-box attack | After PGD, black-box attack | After patch, natural attack | After patch, white-box attack | After patch, black-box attack | |
| Accuracy | 94.9% | 0% | 15.1% | 92.1% | 0% | 9.7% |
| Area under the curve | 0.937 | 0.000 | 0.014 | 0.539 | 0.000 | 0.004 |
| Average confidence level of algorithm in results | 96.1% | 100% | 92.6% | 95.8% | 98.8% | 83.3% |
Similar results were found from attacks on the deep-learning systems developed for fundoscopy and dermoscopy.
Adversarial attacks could affect radiology in a few ways, according to the authors. For example, a company running a clinical trial could effectively guarantee a positive trial result by applying undetectable adversarial perturbations to chest CT images being evaluated by a deep-learning algorithm for an end point such as tumor burden. Furthermore, a bad actor could add adversarial noise to chest x-ray studies -- often used to justify more expensive procedures -- to ensure that a deep-learning model always gives a desired diagnosis.
"For machine-learning researchers, we recommend research into infrastructural and algorithmic solutions designed to guarantee that attacks are infeasible or at least can be retroactively identified," the authors wrote. "For medical providers, payors, and policymakers, we hope that these practical examples can motivate a meaningful discussion into how precisely these algorithms should be incorporated into the clinical ecosystem despite their current vulnerability to such attacks."