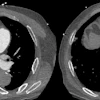
A new risk model for lung cancer goes where Framingham dared to tread for heart disease: providing sophisticated assessments of which individuals would most likely benefit from CT lung screening, according to a report in the August 21 issue of Annals of Internal Medicine.
The Liverpool Lung Project (LLP) risk model was better at predicting lung cancer risk than either smoking history or family history alone, according to researchers from the University of Liverpool and several other U.K. centers, as well as the U.S. National Cancer Institute and the Harvard School of Public Health (Ann Intern Med, Vol. 157:4, pp. 242-250).
"The LLP risk model has a good ability to distinguish persons who will or will not develop lung cancer by using the predicted five-year absolute risk," wrote principal investigator John Field, PhD, from the University of Liverpool's Roy Castle Lung Cancer Research Programme, and colleagues. "The model ... performs better than smoking duration or family history as a tool for deciding which persons to screen for lung cancer."
Maximizing benefit-harm ratio
Analyses of previous lung cancer screening studies have shown the need to identify those individuals who have the highest risk of developing lung cancer, which now kills more than 1 million people a year. The idea is that by maximizing the benefit-harm ratio of CT screening, the technique could be optimized to save the largest number of lives each year.
Unlike some other major diseases, such as breast cancer and heart disease, lung cancer has lacked adequate tools to identify which patients should be targeted to maximize screening's benefits and minimize its potential harms, the authors stated.
Many risk models have been developed to predict individual risk for lung cancer within a specified period by using patient characteristics and epidemiologic, social, and clinical risk factors, including models by Bach et al, Spitz et al, and Tammemagi et al, the group wrote. But such models can be cumbersome to apply in different study populations.
The LLP model could overcome some of these shortcomings. LLP accounts for important risk factors that the others skip, including history of pneumonia, nonlung cancer, and asbestos exposure, as well as family history, making it easier to apply and potentially more useful.
Aiming to test the discriminatory power of the LLP risk model and show its predicted benefit for stratifying individuals for CT lung cancer screening, the study team applied the model to data from three independent studies from Europe and North America.
Three databases
The LLP model was applied to participants in three lung cancer screening projects: the European Early Lung Cancer (EUELC) project, the Harvard case-control study, and the LLP population-based prospective cohort (LLPC) study. The goal was to assess five-year absolute risks for lung cancer predicted by the LLP model, Field and colleagues stated.
Age, smoking, and family histories were similar for individuals in all three projects. In the LLPC, for example, 420 of 7,652 participants (approximately 6% of the cohort) developed lung cancer over an average follow-up of 8.7 years.
There were slightly more cases of lung cancer in men versus women and in participants with a history of pneumonia. There was also approximately triple the risk of lung cancer in participants who had another type of cancer previously.
More predictive power
The LLP risk model had improved accuracy among individuals at greater risk of lung cancer, and it performed well relative to the strong predictor of smoking duration. In addition, the model improved risk assessment compared to a screen-all strategy in all three databases.
The researchers used area under the receiver operator characteristics curve (AUC) values to measure the ability of the model to discriminate which individuals will develop lung cancer from those who will not, with AUC values ranging from 0.5 (no chance) to 1.0 (perfect chance). The LLP model had higher discriminative ability across the three datasets than either smoking history or family history of cancer, with modest discrimination in the EUELC dataset and good discrimination in the Harvard and LLPC datasets, according to the authors.
LLP risk model vs. smoking history by AUC value
|
Field and colleagues also tested the model's performance at different risk levels for developing cancer, ranging from 3% to 15%. At a threshold of 5% absolute risk, for example, the LLP model achieved a greater proportion of true-positive classifications than a strategy of screening all participants (2.3% higher for the LLPC data and 3% higher for the EUELC data), when the proportion of false-positive classifications was held constant.
The researchers evaluated the performance of the model in the three databases using a variety of measurements, as indicated in the table below, based on 5% and 10% cancer risk thresholds.
Performance of LLP risk model by research study
|
||||||||||||||||||||||||||||||||||||||||||||||||||||
The LLP model performed as well as widely used risk factor models for other diseases, such as the Gail model for breast cancer and the Framingham risk score for coronary heart disease, according to the authors.
The investigators cautioned, however, that risk prediction was somewhat variable depending on the study cohort and its limitations. For example, case selection might have trimmed the model's predictive power in the EUELC data because the cohort only included surgically treated patients with non-small cell lung cancers, and the eight different populations in EUELC had varying levels of risk.
"The use of lung cancer risk prediction models to select high-risk patients for lung cancer CT screening is limited, possibly because no model has had rigorous independent testing to determine its effect on patient care," Field and colleagues wrote.
Most trials to date have relied on age and smoking history to identify high-risk individuals for screening, but the strategy assumes similar risk for everyone in a given smoking-risk combination. This approach was good enough when the U.S. National Lung Screening and Nederlands-Leuvens Longkanker Screenings Onderzoek (NELSON) trials were initiated, but the need to identify those most likely to develop lung cancer is now recognized.
Identifying an average risk threshold for a population is complicated by a lack of data on harms, benefits, and real outcomes in a screened population, they wrote.
"Unlike cardiovascular disease, for which a 10-year risk of 20% has been recommended to stratify patients as high-risk, no consensus is available in cancer screening," they wrote.
As for study limitations, a lack of asbestos exposure data in the LLPC study was one shortcoming. In addition, the model looks only at predicted benefits without computing actual outcomes. Finally, data on spirometry measurement and genetic markers were not evaluated, even though they may end up having an important effect on model accuracy.
In an editorial accompanying the report, A. Russell Localio, PhD, from the University of Pennsylvania, and Dr. Steven Goodman, PhD, from Stanford University, wrote that using the LLP model would almost always be better than screening no one or everyone. At the 5% threshold, using the LLP model to determine who should be screened would generate a net benefit of 1.9 true-positive results compared to using the screen-all strategy, they noted.