
Algorithms from the 2023 RSNA Screening Mammography Breast Cancer Detection AI Challenge identified different cancers during screening mammography, suggest findings published August 12 in Radiology.
Researchers led by Yan Chen, PhD, from the University of Nottingham in England, also found that ensemble models that were entered in the challenge had higher sensitivity while maintaining low recall rates.
“The results really highlight the growing readiness of AI to support breast cancer screening programs,” Chen told AuntMinnie. “Our hope is that this challenge will help move the field forward, not just by showcasing promising algorithms, but by highlighting the importance of transparent, collaborative, and clinically focused AI development and evaluation.”
The 2023 RSNA Screening Mammography Breast Cancer Detection AI Challenge invited participants to develop AI models that could independently interpret mammograms, with the overarching goal of rapidly advancing breast imaging AI. The competition attracted 2,146 competitors who formed 1,687 teams, with each team submitting its own AI algorithm.
Chen and colleagues assessed the performance of the submitted algorithms and explored the potential for improving performance by combining the highest-ranked AI algorithms. The researchers also studied how patient characteristics influenced performance in the evaluation cohort.
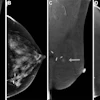
 Right breast mammogram in a 69-year-old woman. There is a 6-mm spiculate mass in the 12 o’clock position (arrow), visible on both the (A) mediolateral oblique and (B) craniocaudal views. This case was not recalled by any of the top 10 AI algorithms but was a biopsy-proven invasive carcinoma. This example from the evaluation dataset is from the Australian site and was acquired using Siemens Healthineers equipment.RSNA
Right breast mammogram in a 69-year-old woman. There is a 6-mm spiculate mass in the 12 o’clock position (arrow), visible on both the (A) mediolateral oblique and (B) craniocaudal views. This case was not recalled by any of the top 10 AI algorithms but was a biopsy-proven invasive carcinoma. This example from the evaluation dataset is from the Australian site and was acquired using Siemens Healthineers equipment.RSNA
Of the total algorithms, the team assessed 1,537 by using an evaluation dataset from two sites, one in the U.S. and one in Australia. They also used pathologic exams to confirm cancer cases and followed up noncancer cases for at least one year.
The evaluation dataset included 5,415 women with a median age of 59. Among the algorithms evaluated, the researchers reported that specificity was high overall, while recall rates were kept low. The top-performing algorithm, meanwhile, had significantly higher sensitivity than the median performance of all algorithms.
Performance of algorithms entered in AI mammography challenge | ||
Measure | Median performance of all algorithms | Top-performing algorithm |
Recall rate | 1.7% | 1.5% |
Sensitivity | 27.6% | 48.6% |
Specificity | 98.7% | 99.5% |
Positive predictive value | 36.9% | 64.6% |
Meanwhile, ensemble models of the top three and top 10 algorithms had a sensitivity of 60.7% and 67.8%, respectively. The corresponding recall rates for these models were 2.4% and 3.5%, while the corresponding specificities were 98.8% and 97.8%.
The team also reported lower sensitivity for the U.S. dataset (52%) compared to the Australian dataset (68.1%). This led to an odds ratio (OR) of 0.51 (p = 0.02). Finally, the researchers observed higher sensitivity for invasive cancers (68%) than for noninvasive cancers (43.8%; OR = 2.73; p = 0.001).
Yan Chen, PhD, further explains the study's findings and their implications on breast care.
Chen said challenges like this show that it’s possible to develop strong AI models using open data and limited computing power. She added that smart design, tuning, and understanding the clinical task are most important.
Chen also said that teams should look beyond the leaderboard at challenges and build systems that reflect real-world complexity.
“We encourage teams to build models that are resilient,” she said. “Those are the models that perform well across different demographics, manufacturers, and clinical environments. That kind of robustness is what makes AI tools trustworthy, scalable, and clinically applicable.”
Chen also told AuntMinnie that the team is working on benchmarking the top-performing algorithms from the challenge against commercial models. The team will use larger, more diverse datasets for this study. The researchers are also exploring the use of smaller-scale datasets with robust human reader performance as a benchmark for evaluating how the algorithms perform. This will include complex and subtle cases that may be encountered in real-world clinical settings.
“Those efforts aim to build a robust evaluation framework, one that supports safe and effective integration of AI into breast cancer screening practices, ultimately benefiting the patients,” she said.
The full study can be found here.
Chen acknowledges the work of her research colleagues on the study and encourages interested AI researchers to become more involved.


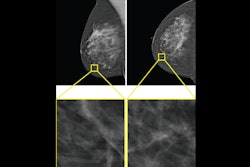






![A normal mammogram confirmed by three-year radiologic follow-up illustrates reader-marked regions of interest (ROIs) during (A) unaided (round 1) and (B) artificial intelligence (AI)–assisted (round 2) reading. Each colored dot represents an ROI for recall by a human reader. Readers could mark more than one ROI per case, represented by multiple dots of the same color. During AI-assisted reading, the AI system displayed three visible prompts: two with suspicion of malignancy scores of 35% (left mediolateral oblique [L MLO] and craniocaudal [L CC]) and one with a suspicion of malignancy score of 10% (right craniocaudal [R CC]), shown as polygonal overlays. Without AI, six of 10 readers (60%) marked a false-positive ROI. With AI assistance, this fell to two of 10 (20%). R MLO = right mediolateral oblique.](https://img.auntminnie.com/mindful/smg/workspaces/default/uploads/2026/07/2026-07-14-radiology-mammogram-ai-auto-bias.H0bYO8QlWs.jpg?auto=format%2Ccompress&dpr=2&fit=crop&h=167&q=70&w=250)



