Physicians far outperformed GPT-5 and five other large language models (LLMs) when interpreting F-18 FDG-PET images of patients with esophageal cancer, a group in Japan has reported.
On a set of 120 images from adult patients who underwent imaging for staging prior to surgery, four physicians with varying experience identified tumor locations with significantly higher accuracy than LLMs, according to the study.
“Although current LLMs have not yet reached physician-level accuracy in comprehensive staging, recent models show promise in assisting with specific diagnostic tasks,” noted corresponding author Yoshitaka Toyama, MD, PhD, of Tohoku University in Sendai, and colleagues. The study was published on February 23 in JMIR Cancer.
Esophagectomy is among the most invasive oncologic surgeries, and optimal patient outcomes depend largely on accurate staging with F-18 FDG-PET imaging. Yet F-18 FDG-PET interpretation is complex and time-intensive, and the diagnostic burden is further exacerbated by significant workforce shortages in both radiology and surgery, the authors explained.
The evolution of multimodal LLMs, which can process and interpret both text and images simultaneously, has recently raised expectations for their potential to fulfill roles in complex medical tasks, the researchers added. Hence, in this study, they assessed the potential of LLMs for staging patients with esophageal cancer.
In the experiment, the performance of six LLMs (GPT-5, GPT-4.5, GPT-4.1, OpenAI-o3, OpenAI-o1, and GPT-4 Turbo) and four human readers (a nuclear medicine specialist, a gastrointestinal surgeon, and two radiology residents) were compared. The task involved identifying the presence of lymph node (LN) involvement (clinical N stage [cN]) and the presence or absence of distant metastasis (clinical M stage [cM]) on 120 FDG-PET images.
According to the results, the average accuracy was 41 of 120 (34%) to 94 of 120 (78%) for the LLMs and 72 of 120 (60%) to 102 of 120 (85%) for physicians, with significantly higher accuracy for physicians ( p < 0.05) in the thoracic LN, abdominal LN, and cN stages.
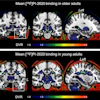
 Examples of input images and responses of GPT-4.5, GPT-4.1, and OpenAI-o3 in cases of esophageal cancer. The primary tumor site indicated in the radiology report is shown as a blue circle, and the metastatic LNs are shown as red circles. Note that these colored circles were manually overlaid by the authors to visualize the ground truth and were not generated by the AI models. The yellow cells indicate the correct answers (agreement with the ground truth). (A) All the models correctly identified the absence of LN and distant metastases beyond the primary lesion. (B) A case with a single metastatic thoracic LN. Only GPT-5 and OpenAI-o1 provided a correct evaluation, identifying thoracic LN metastasis, no abdominal LN metastasis, and the correct cN and cM stages. Other models either failed to identify the thoracic LN metastasis or misdiagnosed abdominal LN metastasis as positive. (C) A cN-stage 2 case with thoracic LN metastasis. F-18 FDG accumulation in the hilar LNs was interpreted as nonspecific accumulation in the radiology report. GPT-5 correctly identified the cN stage but misdiagnosed abdominal LN metastasis as positive. Although other models correctly identified thoracic LN metastasis, many incorrectly stated the disease as N1. JMIR Cancer
Examples of input images and responses of GPT-4.5, GPT-4.1, and OpenAI-o3 in cases of esophageal cancer. The primary tumor site indicated in the radiology report is shown as a blue circle, and the metastatic LNs are shown as red circles. Note that these colored circles were manually overlaid by the authors to visualize the ground truth and were not generated by the AI models. The yellow cells indicate the correct answers (agreement with the ground truth). (A) All the models correctly identified the absence of LN and distant metastases beyond the primary lesion. (B) A case with a single metastatic thoracic LN. Only GPT-5 and OpenAI-o1 provided a correct evaluation, identifying thoracic LN metastasis, no abdominal LN metastasis, and the correct cN and cM stages. Other models either failed to identify the thoracic LN metastasis or misdiagnosed abdominal LN metastasis as positive. (C) A cN-stage 2 case with thoracic LN metastasis. F-18 FDG accumulation in the hilar LNs was interpreted as nonspecific accumulation in the radiology report. GPT-5 correctly identified the cN stage but misdiagnosed abdominal LN metastasis as positive. Although other models correctly identified thoracic LN metastasis, many incorrectly stated the disease as N1. JMIR Cancer
“These statistical findings confirm that, despite some overlapping accuracy ranges, current general-purpose LLMs reliably underperform compared with human experts in complex staging tasks,” the researchers wrote.
The results were not entirely unexpected, the investigators noted. As LLMs are primarily trained on textual data, they excel in natural language understanding and reasoning, but to date, they lack the capability to process and analyze complex visual information, they wrote.
“To improve accuracy, future research should prioritize architectures that better integrate text and visual data. Incorporating multimodal learning frameworks that combine textual and imaging information might enhance diagnostic performance and facilitate clinical applicability,” the group concluded.
The full study is available here.