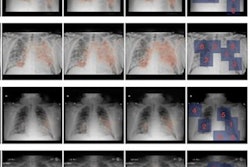
Promising results were reported in 2020 for many artificial intelligence (AI)-based image analysis algorithms for COVID-19 applications. But none of these reports are sufficient to support the readiness of AI for clinical use, according to a new U.K. study.
In a literature review published online March 15 in Nature Machine Intelligence, researchers led by Michael Roberts, PhD, of the University of Cambridge in the U.K. detailed methodological flaws and/or underlying biases in all 62 scientific papers they reviewed on the use of AI in chest CT or chest radiography for COVID-19 patients.
These shortcomings included, for example, reliance on "Frankenstein" image datasets that are assembled from other datasets and given a new identity.
"In their current reported form, none of the machine-learning models included in this review are likely candidates for clinical translation for the diagnosis/prognosis of COVID-19," the authors wrote. "Higher-quality datasets, manuscripts with sufficient documentation to be reproducible and external validation are required to increase the likelihood of models being taken forward and integrated into future clinical trials to establish independent technical and clinical validation as well as cost-effectiveness."
None of the papers published from the review period of January 1 to October 3 met all three of the group's criteria:
- A sufficiently documented manuscript describing a reproducible method
- A method that follows best practice for developing a machine-learning model
- Sufficient external validation to justify the wider applicability of the method
"Many studies are hampered by issues with poor-quality data, poor application of machine-learning methodology, poor reproducibility and biases in study design," the authors wrote.
For example, several training datasets used pediatric images for their non-COVID-19 data and images from adults for their COVID-19 data.
"However, since children are far less likely to get COVID-19 than adults, all the machine-learning model could usefully do was to tell the difference between children and adults, since including images from children made the model highly biased," Roberts said in a statement from the University of Cambridge.
In addition, many of the models were trained on sample datasets that were too small to be effective, or the studies didn't specify where their data had come from. Also, the models may have been trained and tested on the same data or were based on publicly available "Frankenstein" datasets that had evolved and merged over time. This made it impossible to reproduce initial study results, according to the researchers.
The authors noted that the lack of involvement from radiologists and clinicians was another widespread flaw seen in many of the studies.
"Whether you're using machine learning to predict the weather or how a disease might progress, it's so important to make sure that different specialists are working together and speaking the same language, so the right problems can be focused on," Roberts said.
The researchers cautioned against the naive use of public datasets, which can lead to significant risk of bias. Datasets should be diverse and appropriately sized to make AI models useful for different demographic groups. Finally, independent external datasets should be curated, they said.
They also emphasized that manuscripts need to provide sufficient documentation to be reproducible. External validation is also required to increase the likelihood of models being integrated into future clinical trials needed to establish independent technical and clinical validation, as well as cost-effectiveness, according to the authors.