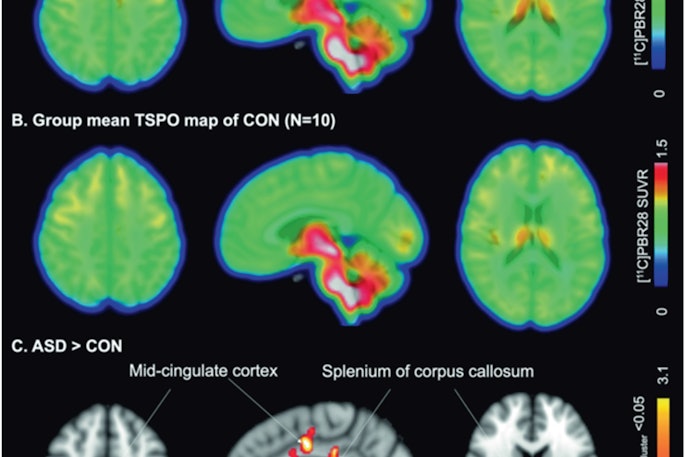
Top Story


Latest News

Sponsored
My BreastAI Suite by GE HealthCare
April 2, 2024

POCUS used widely in lung ultrasound applications
April 17, 2024


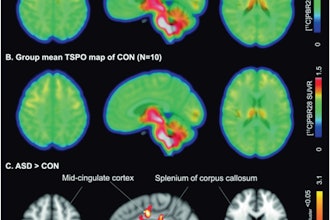



More from AuntMinnie
AdvaMed urges Congress prioritize R&D tax credit
April 17, 2024


Swoop system tested in Alzheimer’s patients
April 17, 2024

PET tracer for gliomas under expedited review
April 17, 2024


Matsumoto named chair of ACR Board of Chancellors
April 16, 2024

SNMMI declares win in Washington, DC
April 16, 2024

ACR lays off 11% of workforce
April 16, 2024



