Europe
Clinical News
Informatics
Industry News
Practice Management
Education
Subspecialties
More
Sign In
myAuntMinnie
CME
Careers
Cases
Forums
Conferences
Videos
Webinars
Advertising
Buyer's Guide
Vendors
Top Story
CT
Clinical practice LCS program finds more disease than NLST
Over a five-year period, a clinical practice lung cancer screening program at Duke University Medical Center in Durham, NC, found more disease than did the National Lung Screening Trial (NLST), researchers have reported.
Featured
Molecular Imaging
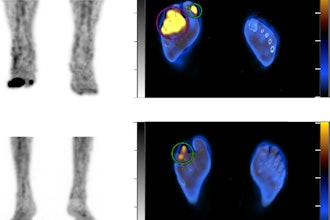
SPECT/CT predicts foot amputations in diabetics
Ultrasound
Deep-learning algorithm improves liver fibrosis diagnosis
Latest News
Radiologists can take steps toward environmental sustainability
April 23, 2024
Novel risk prediction model improves LCS uptake
April 23, 2024
Sponsored
Register today for a FREE webinar May 8 at 12 Noon EDT
April 24, 2024
NLP uncovers racial bias in documenting ob/gyn imaging findings
April 23, 2024
Cases of the Week
Check out our Cases of the Week!
70-year-old man with abdominal pain
A 70-year-old man with a history of right middle lobe lobectomy for metastatic renal cell carcinoma one day prior developed abdominal pain.
Woman in her 60s with hypertension
80-year-old man presenting for follow-up imaging of abdominal lesion
View All Cases
Clinical News
CT
Clinical practice LCS program finds more disease than NLST
Molecular Imaging
SPECT/CT predicts foot amputations in diabetics
Ultrasound
Deep-learning algorithm improves liver fibrosis diagnosis
CT
Novel risk prediction model improves LCS uptake
Imaging Informatics
Ultrasound
Deep-learning algorithm improves liver fibrosis diagnosis
Artificial Intelligence
NLP uncovers racial bias in documenting ob/gyn imaging findings
Artificial Intelligence
Can ChatGPT ‘data mine’ patient reports for stroke registries?
Artificial Intelligence
Blackford and Lucida Medical partner on prostate cancer imaging
Industry News
MRI
Hyperfine highlights abstracts to be presented at ISMRM 2024
Womens Imaging
Beyond2020 highlights AI-powered mammography services in Costa Rica
POCUS
Exo launches cardiac, lung AI apps for Exo Iris
Image-Guided Surgery
FDA clears Philips Zenition 30 mobile C-arm
Artificial Intelligence
Deep-learning algorithm improves liver fibrosis diagnosis
An algorithm combining the Fibrosis-4 Index and an ultrasound deep-learning model could improve diagnostic accuracy for advanced liver fibrosis.
NLP uncovers racial bias in documenting ob/gyn imaging findings
Can ChatGPT ‘data mine’ patient reports for stroke registries?
More Artificial Intelligence
More from AuntMinnie
Hyperfine highlights abstracts to be presented at ISMRM 2024
By
AuntMinnie.com staff writers
Hyperfine is highlighting 17 ultralow-field MRI-related abstracts to be presented at the 2024 ISMRM annual meeting in Singapore.
April 23, 2024
Beyond2020 highlights AI-powered mammography services in Costa Rica
By
AuntMinnie.com staff writers
Beyond2020 is highlighting the deployment of AI-powered mammography services across Costa Rica to support women living in underprivileged areas.
April 23, 2024
Exo launches cardiac, lung AI apps for Exo Iris
By
AuntMinnie.com staff writers
Exo’s cardiac and lung AI applications are now available on Exo Iris, its handheld ultrasound device.
April 23, 2024
Neuroimaging detects blast exposure brain injuries in U.S. soldiers
By
Will Morton
A battery of MRI and PET neuroimaging tests show patterns of brain injury in active-duty U.S. soldiers caused by repeated blast exposures.
April 22, 2024
FDA clears Philips Zenition 30 mobile C-arm
By
AuntMinnie.com staff writers
Philips parent Royal Philips has secured clearance from the U.S. Food and Drug Administration (FDA) for its Zenition 30 mobile C-arm.
April 22, 2024
CT cerebral angiography ED headache diagnosis more effective
By
AuntMinnie.com staff writers
CT cerebral angiography makes emergency department (ED) diagnosis of headache more effective, researchers have found.
April 22, 2024
American Shared Hospital Services mourns passing of CEO
By
AuntMinnie.com staff writers
American Shared Hospital Services (ASHS) is mourning the sudden passing of its CEO, Peter Gaccione.
April 22, 2024
GE expands collaboration with Elekta via MIM subsidiary
By
AuntMinnie.com staff writers
GE HealthCare (GEHC) is collaborating with Elekta through its recent acquisition, MIM Software.
April 22, 2024
Mobile health screening model lowers costs, promotes sustainability
By
Amerigo Allegretto
A new cancer screening service model can reduce costs and improve environmental sustainability for breast cancer screening and other screening exams.
April 22, 2024
What's brewing in RT and RA legislation, policy, and standards?
By
Liz Carey
A range of federal and state legislation and other developments in the works could have a significant impact on radiologic technologists and registered radiology assistants.
April 22, 2024
Evergreen Theragnostics raises $26M
By
AuntMinnie.com staff writers
Evergreen Theragnostics has completed a $26 million capital raise through its existing shareholders and new backers Petrichor and LIFTT.
April 19, 2024
MR elastography effective for assessing liver stiffness in children
By
Kate Madden Yee
MR elastography is an effective technique for noninvasive monitoring of liver stiffness -- a surrogate for fibrosis -- in children and young adults with autoimmune liver disease, researchers have reported.
April 19, 2024