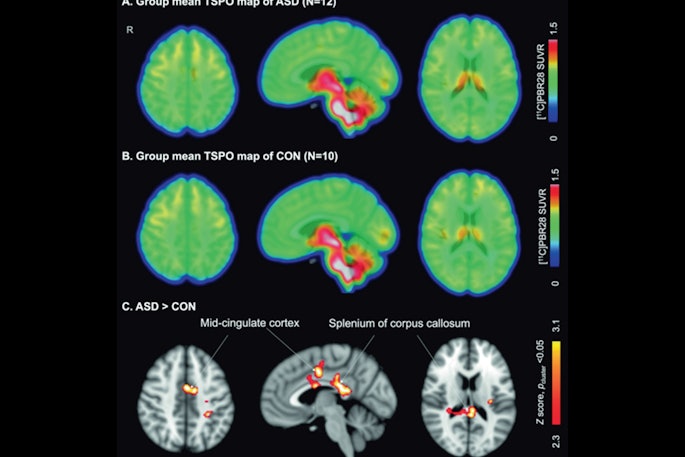
Top Story


Latest News

Sponsored
We care about what you think.
October 30, 2023






More from AuntMinnie

Accuray opens training facility in Switzerland
April 18, 2024

Lumicell's Lumisight, LumiSytem get FDA nods
April 18, 2024

Radiology Leadership Institute names award recipients
April 18, 2024

GE HealthCare launches two new ultrasound systems
April 18, 2024
AdvaMed urges Congress prioritize R&D tax credit
April 17, 2024


Swoop system tested in Alzheimer’s patients
April 17, 2024

PET tracer for gliomas under expedited review
April 17, 2024


Matsumoto named chair of ACR Board of Chancellors
April 16, 2024
